NVIDIA Unveils the DGX-1 HPC Server: 8 Teslas, 3U, Q2 2016
by Ryan Smith & Ian Cutress on April 6, 2016 8:00 AM EST_678x452.jpg)
For a few years now, NVIDIA has been flirting with the server business as a means of driving the growth of datacenter sales of their products. A combination of proof-of-concept hardware configurations and going into spaces not necessarily served right away by the OEMs, NVIDIA has over the years put together boxes like their Quadro Visual Computing Appliance and the DIGITS devbox. Though a side business for NVIDIA, it’s one that has taken on some importance, and nowhere is this more applicable than with the Pascal-based Tesla P100 announced this week.
One of the more interesting aspects we’ve known about P100 for some time now – and well before the product was formally announced this week – was that NVIDIA would be pursuing a new form factor and new interconnect technology. Though the GP100 GPU at the heart of the P100 supports traditional PCI Express, NVIDIA has also invested heavily in NVLink, their higher-speed interconnect to enable fast memory access between GPUs, and unified memory between the GPU and CPU. For NVIDIA this is a logical progression: as GPUs become increasingly CPU-like in their flexibility and necessity, they move from being a peripheral to a core processor, and so too must their I/O and form factor evolve to match.

This brings us back to servers. Because NVIDIA is launching P100 with a new form factor and connector, P100 requires completely new infrastructure to run. NVIDIA’s OEM partners will in successive quarters be offering their own systems supporting P100 and its mezzanine connector, but right now at day 1 there is nothing from the OEMs ready to support P100. So in order to avoid the long gap for OEM servers to catch up, to serve as a pathfinder for their own development of P100 and its software, and to further their own goals for the server market, NVIDIA is producing their own P100 server – the first P100 server – the full scale DGX-1.
I call DGX-1 a full-scale server because it is a maximum implementation of Tesla P100 right off the bat. 8 P100s are installed in a hybrid mesh cube configuration, making full use of the NVLink interconnect to offer a tremendous amount of memory bandwidth between the GPUs. Each NVLink offers a bidirectional 20GB/sec up 20GB/sec down, with 4 links per GP100 GPU, for an aggregate bandwidth of 80GB/sec up and another 80GB/sec down.
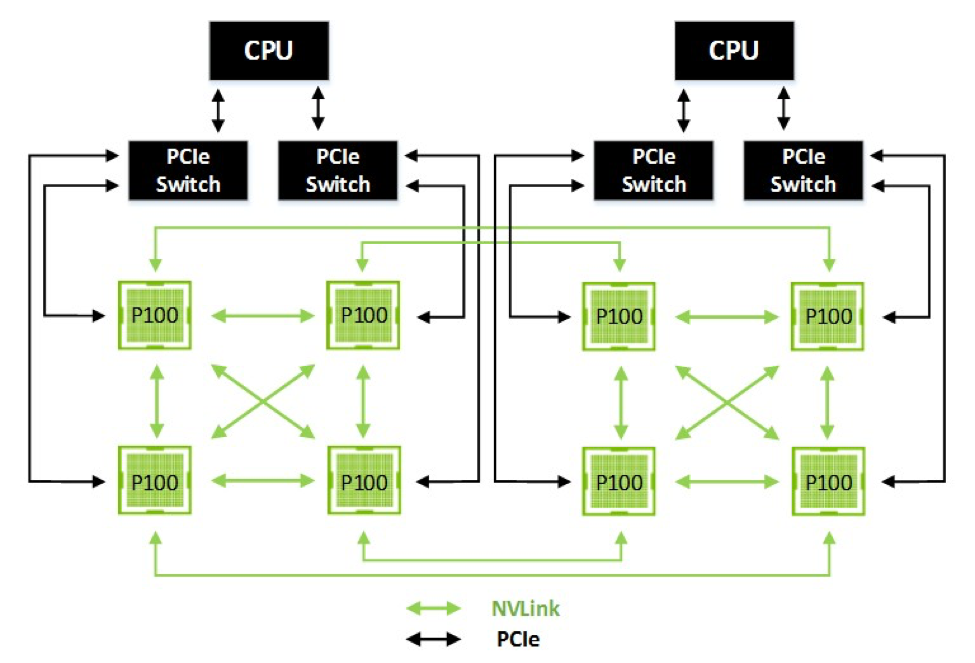
The mesh itself is a Non-Uniform Memory Access (NUMA) style design; with 4 links, not every GPU can be linked to every other GPU. But in the case where two GPUs aren’t linked, the next GPU is no more than 1 hop away. Meanwhile, the GPUs connect back to their x86 CPU host over standard PCI Express.
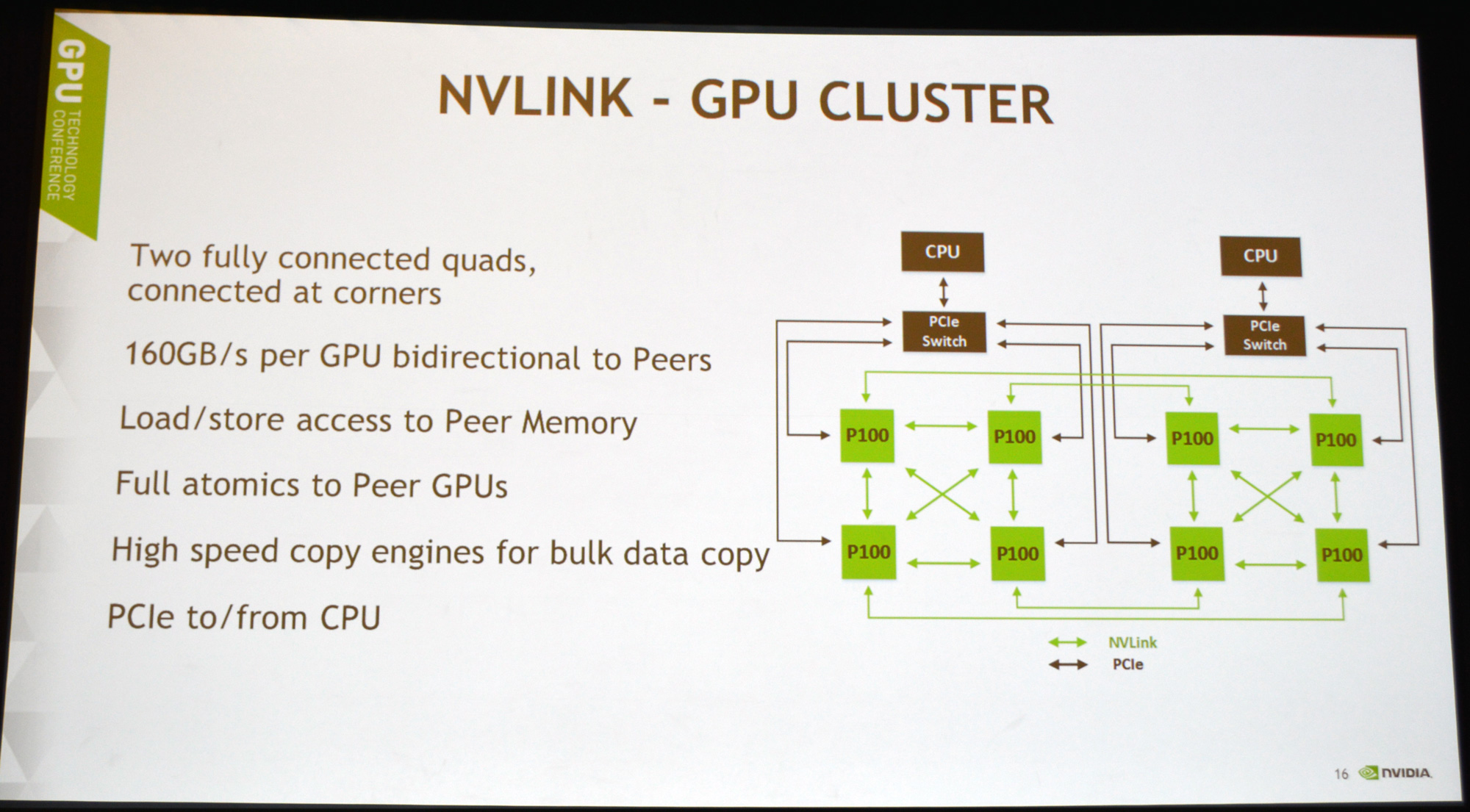
NVLink in turn enables each GPU to directly execute read, write, and atomic memory operations out of the memory of the other GPUs, functionality that has not been available to NVIDIA GPUs before. For this reason, NVIDIA has not shied away from pointing out that while NVLink may technically be an interconnect, it’s really more of a memory technology, which would make data transference one such application of the technology. Fundamentally this ends up being a very different take on an interconnect than PCI Express, which is a data bus with certain memory-like features layered on top of it. In this case it’s probably safe to say that NVLink is closer to the likes of Intel’s QPI and AMD’s HyperTransport.
Getting back to the server itself, backing up the P100s is a hefty dual Intel Xeon based system. The DGX-1’s 3U chassis holds a dual 16-core Xeon E5-2698 v3 arrangement, 512 GB of DDR4-2133 LRDIMMs, four Samsung PM863 1.92 TB storage drives, dual 10 gigabit Ethernet (10GBase-T) as well as four EDR Infiniband connections. This system serves not only to feed the Teslas, but to further drive home NVIDIA’s scalability goals as well, with the Infiniband connections in particular put in place to allow for high-performance DGX-1 clusters. Of course with so much hardware on hand you’ll need a lot of power to drive it as well – 3200W, to be precise – as the 8 P100s alone can draw up to 2400W.
| NVIDIA DGX-1 Specifications | |||
| CPUs | 2x Intel Xeon E5-2698 v3 (16 core, Haswell-EP) | ||
| GPUs | 8x NVIDIA Tesla P100 (3584 CUDA Cores) | ||
| System Memory | 512GB DDR4-2133 (LRDIMM) | ||
| GPU Memory | 128GB HBM2 (8x 16GB) | ||
| Storage | 4x Samsung PM863 1.92TB SSDs | ||
| Networking | 4x Infiniband EDR 2x 10GigE |
||
| Power | 3200W | ||
| Size | 3U Rackmount | ||
| GPU Throughput | FP16: 170 TFLOPs FP32: 85 TFLOPs FP64: 42.5 TFLOPs |
||
In terms of construction, as hinted by in NVIDIA’s sole diagram of a component-level view of the DGX-1, the Tesla cards sit on their own carrier board, with the Xeon CPUs, DRAM, and most other parts occupying their own board. The carrier board in turn serves two functions: it allows for a dedicated board for routing the NVLink connections – each P100 requires 800 pins, 400 for PCIe + power, and another 400 for the NVLinks, adding up to nearly 1600 board traces for NVLinks alone – and it also allows easier integration into OEM designs, as OEMs need only supply an interface for the carrier board. It’s a bit of an amusing juxtaposition then, as the carrier board essentially makes for one massive 8 GPU compute card, being fed with PCIe lanes from the CPU and power from the PSU.

On a quick aside, I also asked NVIDIA about cooling for the P100s, given that there’s 2400W of them to cool. While they aren’t going into great detail about the heatsinks used (e.g. whether there are any vapor chambers involved), they did confirm that they are 2U tall heatsinks, and as NVIDIA is wont to do, the tops are painted green. Apparently these are the standard heatsinks for P100, and when OEMs start assembling their own systems, these will be the heatsinks that come with the boards.

Meanwhile, besides the practical necessity of constructing the DGX-1 as the pathfinder system and reference implementation for the P100, at the end of the day the DGX-1 is meant to be a workhorse for NVIDIA’s customers. Given its 8 P100s we’re looking at 28,672 CUDA cores and 128GB of shared VRAM, the DGX-1 is rated to be able to hit 170 FP16 TFLOPs of performance (or 85 FP32 TFLOPs) inside of 3Us. And though the server should be good at just about any HPC task given the versatility offered by the P100 – it offers fast FP64 and ECC as well – NVIDIA is initially pitching the box at the deep learning/neural network market, where they’re intending to fully exploit the FP16 performance improvements of the Pascal architecture. NVIDIA has of course been building towards this market for some time now, and it is their hope that DGX-1 combined with their ever-increasing collection of tools and SDKs (cuDNN, DIGITS, etc) that this will serve as a catalyst for that market.
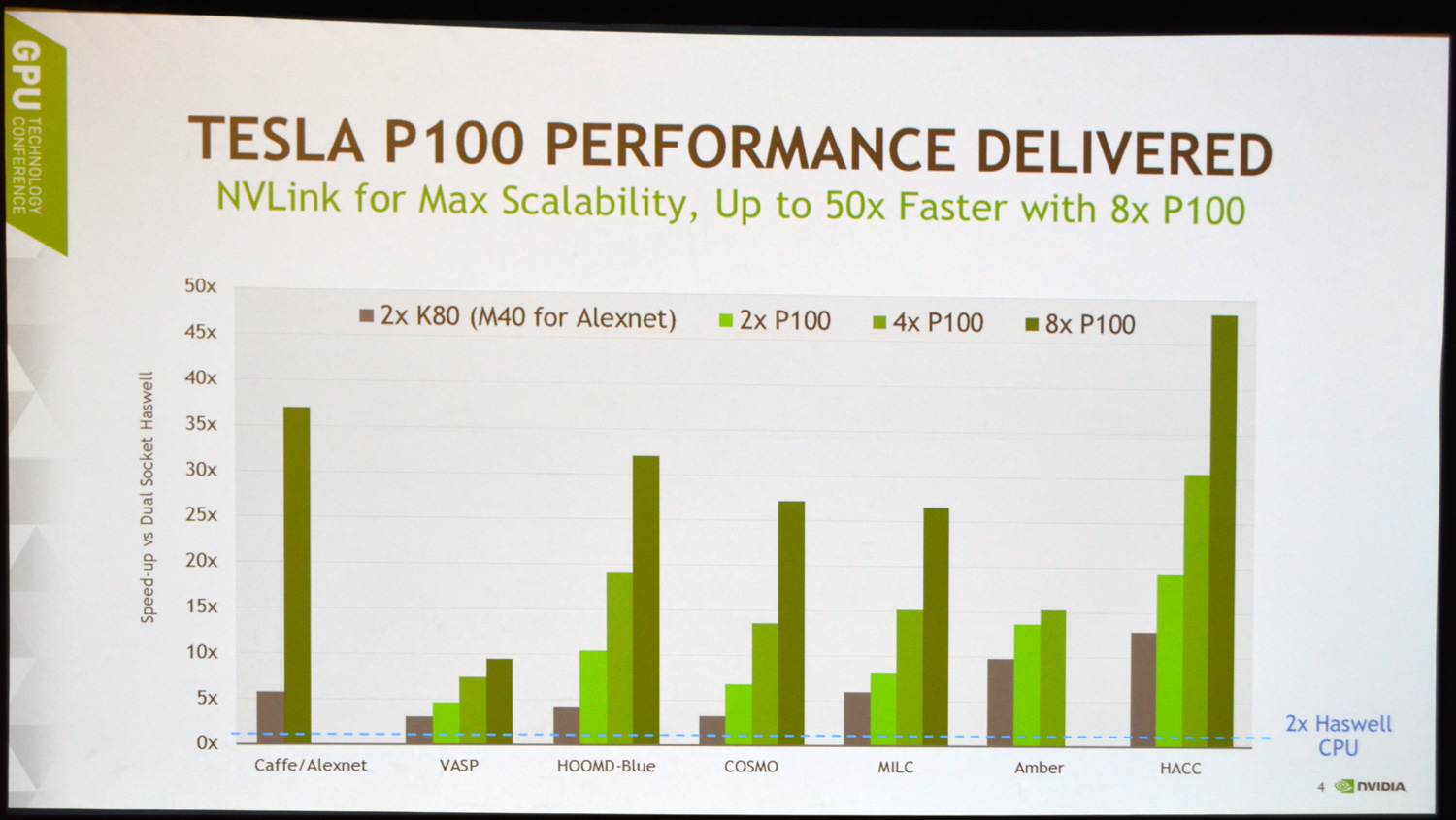
The same can be said as well about the server space in general. Producing their own server does put NVIDIA in competition with their OEM partners to some degree, but in chatting with NVIDIA they have made it very clear that this isn’t a long-term strategy – that they don’t want to be a full-fledged server vendor. Rather the DGX-1 is the tip of the spear as the first P100 system, and is meant to create and spur on the market, which is where the OEMs will step in next year with their own, far larger variety of systems.
In the meantime, with OEM Tesla P100-equipped systems not set to ship until Q1 of 2017, for the next couple of quarters the DGX-1 will be the only way for customers to get their hands on a P100. The systems will be production quality, but they are nonetheless initially targeted at early adopters who want/need P100 access as soon as possible, with a price tag to match: $129,000.

It goes without saying that NVIDIA seems very confident that they’ll sell plenty of systems at this price, and while it’s not being said by anyone at NVIDIA, I think it’s reasonable to assume that the high price tag is the tradeoff customers will have to make to get P100 so soon. The underlying (and massive) GP100 GPU is in full volume production, but it’s difficult to imagine chip yields are spectacular, even for the cut-down 56 SM configuration used on P100. Rather it’s that NVIDIA is willing to go into volume production now and sell GP100-based products so early because HPC customers will pay such a high price, essentially eating the cost of low yields in order to get the good GPUs that come out of TSMC ASAP.
Anyhow, NVIDIA has already begun taking pre-orders of the systems over on their website. The first systems will be shipping in May to various research universities; what NVIDIA calls their pioneers. After that, DGX-1 boxes will begin shipping to their close partners and customers in the rest of Q2. Notably (and a bit surprisingly), Q2 not only includes NVIDIA’s close partners, but general pre-order customers as well. So for those customers who got their pre-orders in early enough yesterday to get one of the first servers, they should be able to get their hands on DGX-1 and the Tesla P100s inside by the end of June.
Source: NVIDIA








31 Comments
View All Comments
SaolDan - Wednesday, April 6, 2016 - link
Neat!slayek - Wednesday, April 6, 2016 - link
Neat. I am wondering what softwares can take theses beast into good use? A lot of computational chemistry software still uses no CUDA or if they do, use it for simple stuff.Eidigean - Wednesday, April 6, 2016 - link
SpaceX uses NVIDIA GPUs to simulate the chemical mixing within virtual combustion chambers, down to the molecular and nanosecond scales, while designing their methane-based Raptor engine. They've been waiting for NVLink to speed up their work even further.Here is their demonstration while lecturing at GPU Technology Conference (I've queued it up to where it gets interesting, but feel free to rewind and watch it all) https://youtu.be/vYA0f6R5KAI?t=1456
Shadow7037932 - Wednesday, April 6, 2016 - link
That was an interesting presentation. Thanks for the link.esoel_ - Wednesday, April 6, 2016 - link
But does it run crysis in VR ?Jon Tseng - Wednesday, April 6, 2016 - link
... With Iray ray tracing...madwolfa - Wednesday, April 6, 2016 - link
But will it run Crysis..?Jokes aside... great looking machine. The amount of horsepower packed in one box is astonishing.
bill.rookard - Wednesday, April 6, 2016 - link
As is the power consumption. The GPUs are allegedly rated at about 300w each, along with two high-core count Xeons and associated hardware. At full tilt, these things could be pushing almost 3kw. There is no such thing as a free ride... and those are pretty darn impressive machines.madwolfa - Wednesday, April 6, 2016 - link
"ASCI White consumed 3 megawatts of power. The DGX-1 will consume ~3 KW (maybe a little less, I doubt they'd design it to run at >90% power supply spec). So 3.44x the performance for >1000x less power. ~3500x more energy efficient."https://www.reddit.com/r/hardware/comments/4dhh0s/...
webdoctors - Wednesday, April 6, 2016 - link
Just amazing how far we've come in 10 years.