Original Link: https://www.anandtech.com/show/15971/intels-11th-gen-core-tiger-lake-soc-detailed-superfin-willow-cove-and-xelp
Intel’s 11th Gen Core Tiger Lake SoC Detailed: SuperFin, Willow Cove and Xe-LP
by Dr. Ian Cutress on August 13, 2020 9:01 AM EST- Posted in
- CPUs
- Intel
- SoCs
- Tiger Lake
- 10+
- Xe-LP
- Willow Cove
- Intel Arch Day 2020
- SuperFin
- 10SF

At the start of the year, Intel ‘foolishly’ handed me a wafer of its next generation Tiger Lake processors, as the moment it came into my hands I attempted to make a very quick exit. In my time with the wafer, we learned that this new 10nm laptop-focused processor had four cores, used Intel’s next generation Xe graphics architecture, and would set the stage at the end of the year as the cornerstone of Intel’s mobile processor offerings. As part of Intel’s Architecture Day 2020 a couple of days ago, the company went into detail about what makes Tiger Lake the true vehicle for 10nm, and why customers will want a Tiger Lake device.

Intel Architecture Day 2020, August 11th
Before we start into the information about Tiger Lake, I want to start by saying that the information in this article, as well as our coverage on Xe graphics and a number of upcoming mini-stories, all stems from Intel’s Architecture Day 2020 event. Building upon the success of the event in 2018, press and enthusiasts alike have continually asked when Intel would be doing it again. No doubt trying to pin down 20+ senior engineers and executives for an event at the same time in the same location is tough, and due to COVID this event was delayed at least twice.
Despite this, Intel made Arch Day 2020 a virtual event, allowing the engineers to pre-record their segments. The event was held behind closed doors, as with the 2018 event, the embargo lift was set for 1-2 days after. As a result, the articles you see published today are at the end of a lack of sleep between the event and now, as Intel went very dense very quickly (that’s a good thing™). We’ve digested as much as we can in that short space of time, we’ve asked some initial questions, but no doubt more will be asked as further analysis occurs.

The event was headlined by an effervescent Raja Koduri, who took the role of covering roadmaps and some of the Xe structural details. Prominent Intel Fellows and Engineers were the stars of the show in my eyes, particularly Ruth Brain (transistors), Ramune Nagisetty (packaging), Boyd Phelps (Tiger Lake), David Blythe (Xe GPU), Lisa Pierce (GPU software), Sailesh Kottapalli (Xeon) and others, all covering aspects of Intel’s strategy and portfolio.

Along with this article today covering Tiger Lake, we have an article going into the Xe graphics disclosures today as well. There are a number of mini-highlights from the event I also want to cover, and these will be published over the next few days.
Intel’s 11th Gen Core Tiger Lake SoC Detailed: Willow Cove and Xe-LP
Timeline: Tiger Lake will be Intel’s 11th Gen Core
Intel first unveiled its Core microarchitecture in Q1 2006, as an offshoot of the more power efficient Pentium Pro products. This was decided because the leading edge Intel products of the day, based on Netburst, were fast but hot and power hungry. By going down the route of Core, starting with Conroe, Intel has delivered multiple generations of products with the goal at each step to improve performance, power efficiency, and introduce better ways to perform compute.
| Intel's Core Family | |||||
| Gen | Year | Process | Core | Graphics | SoC |
| 1st Gen Core | 2006 | 65nm | Conroe | - | Core 2 |
| 2008 | 45nm | Nehalem | - | Lynnfield | |
| 2010 | 32nm | Westmere | Gen5 | Clarkdale | |
| 2nd Gen Core | 2011 | 32nm | Sandy Bridge | Gen6 | Sandy Bridge |
| 3rd Gen Core | 2012 | 22nm | Ivy Bridge | Gen7 | Ivy Bridge |
| 4th Gen Core | 2013 | 22nm | Haswell | Gen7.5 | Haswell |
| 5th Gen Core | 2015 | 14nm | Broadwell | Gen8 | Broadwell |
| 6th Gen Core | 2015 | 14nm | Skylake | Gen9 | Skylake |
| 7th Gen Core | 2017 | 14+ | Kaby Lake | Gen9 LP | Kaby Lake |
| 8th Gen Core | 2017 | 14++ | Coffee Lake | Gen9 LP | Coffee Lake |
| 2017 | 10 minus | Palm Cove | Gen10* | Cannon Lake | |
| 2018 | 14++ | Whiskey Lake | Gen9 LP | Whiskey Lake | |
| 2019 | 14+ | Amber Lake | Gen9 LP | Amber Lake | |
| 9th Gen Core | 2018 | 14++ | Coffee Lake | Gen9 LP | Coffee Lake-R |
| 10th Gen Core | 2019 | 14+++ | Comet Lake | Gen9 | Comet Lake |
| 2019 | 10nm | Sunny Cove | Gen11 | Ice Lake | |
| 11th Gen Core | 2020 | 10SF | Willow Cove | Xe-LP | Tiger Lake |
| *Cannon Lake's Gen10 was never enabled | |||||
[table – year, generation, process node, core, soc]
Intel uses a lot of code names for its cores and for its products. The marketable names that get printed on the side of the retail box are do with ‘9th Generation Core’, however because we are dealing with the finer details of these products and cores, we prefer to use the code names. Keep this cheat sheet if the number of code names starts getting dense.
Tiger Lake pairs Willow Cove with Xe-LP
At its heart, the current Tiger Lake processor being presented by Intel is a four core mobile-series processor aimed at the 15 W target market where premium ultra-portable notebooks exist. Inside is four cores based on Intel’s Willow Cove architecture, the next generation after Sunny Cove, which we saw in Ice Lake. The four cores will be paired with 96 Execution Units of the new Xe-LP graphics architecture, and Tiger Lake will be Intel’s first product with Xe-LP.

Compared to Intel’s current generation product in this space, its Ice Lake processor, the number of CPU cores stays the same, but we move from a Sunny Cove core design to a Willow Cove core design, which has performance benefits we will detail later. Graphics is boosted in raw numbers by +50%, moving from 64 EUs to 96 EUs, however the architecture change from Ice Lake’s Gen11 design to the new Xe-LP affords additional performance benefits.
Tiger Lake also includes on-silicon support for technologies such as Thunderbolt 4, USB 4, PCIe 4.0, LPDDR5, as well as dedicated IP for total memory encryption and an updated Gaussian Neural Accelerator (to help with noise cancellation and similar functionality). We cover these on our page about Tiger Lake’s IO and sub-system.
No Longer on 10+, new 10nm SuperFin Technology
Tiger Lake uses Intel’s 10nm ‘SuperFin’ manufacturing process technology. As part of this launch, Intel has replaced the 10+ nomenclature and instead renamed it to 10nm SuperFin, or 10SF. This is in part due to some of the updates Intel has made to its 10nm process in order to enable some of the features in Tiger Lake.
The SuperFin technology includes a new high performance transistor methodology for the critical paths of Intel’s design, and an improved metal stack which uses novel materials in the latest update to Intel’s FinFET process technology. This includes evolutionary changes to achieve the required performance characteristics that perhaps should have been part of Intel’s 10nm process from the beginning.
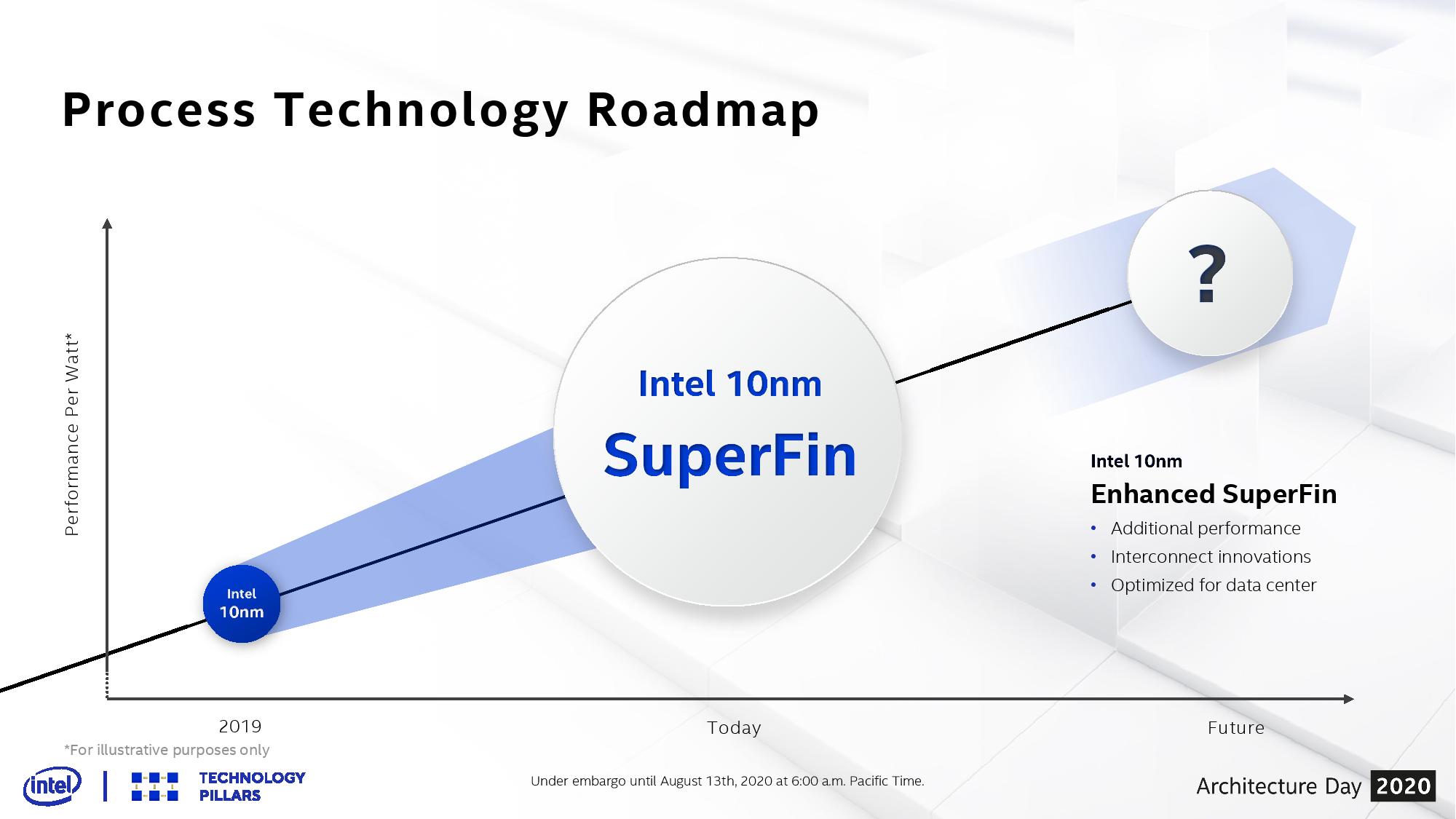
We will also cover the new SuperFin over the course of our Intel Architecture Day coverage.
Intel has also renamed the generation after 10nm SuperFin, and called it 10nm Enhanced SuperFin, or 10ESF for short. This comes into play with some of Intel’s future products, such as its high performance computing GPU called Ponte Vecchio, as well as the next generation Xeon Scalable platform called Sapphire Rapids.
Tiger Lake Goals: Bigger and Better than Ice Lake
As part of Intel’s disclosures about Tiger Lake and specifically to talk on Willow Cove, Intel’s Boyd Phelps, the Tiger Lake SoC Lead Architect, spoke about how the new design, coupled with the new manufacturing technology, enables the new core to offer better performance and better performance efficiency at every point of the curve compared to Ice Lake.
As part of the design of Tiger Lake, Intel had two options on how to build on the Ice Lake design: push further with better single thread performance / IPC, or drive performance and efficiency. Intel ultimately focused more on the latter, as the engineers felt that it would enable a bigger leap in performance over the Ice Lake design.
This means that the new cores in Tiger Lake a built that for any given power or voltage, they will run at a higher frequency. Or for any given frequency, Tiger Lake will require a lower voltage. Where Ice Lake essentially topped out at 4.0 GHz within that 15 W window, Tiger Lake will start pushing numbers back up to 5.0 GHz.
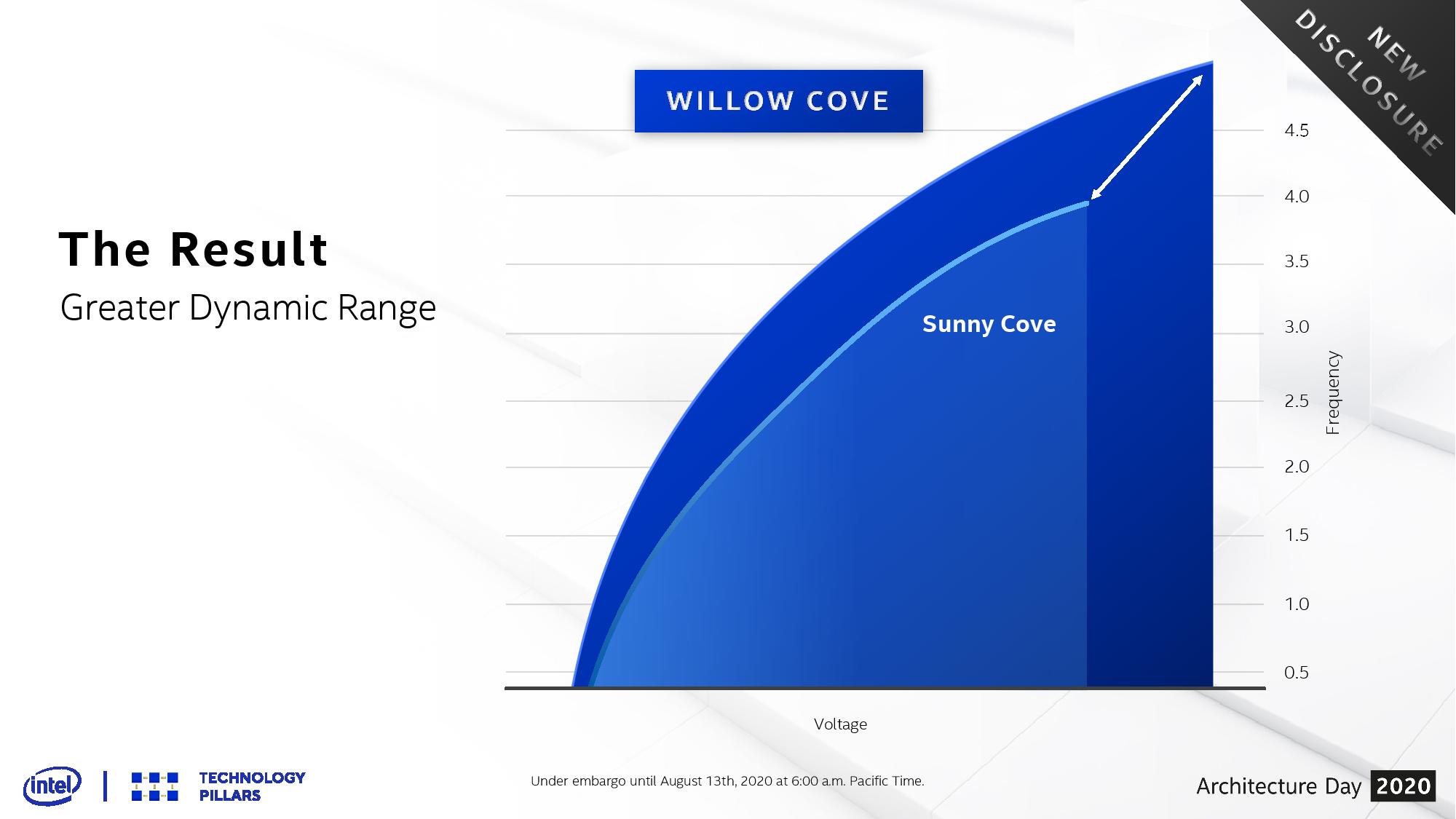
This is important – when we reviewed Ice Lake, it was a bit of an odd situation. At the time, Intel’s main comparison point was its previous generation Whiskey Lake processors. Ice Lake afforded a raw 15-20% performance uplift against Whiskey Lake at the same frequency, which in general is a very good metric to have. However, Ice Lake was 10-20% lower on frequency, effectively nullifying all of those gains. At the same power, Ice Lake had a hard time beating the previous generation.
With Tiger Lake then, the stage seems to be set that the raw performance in frequency alone is going to jump anywhere from 10-20% depending on how the turbo modes are set to work in the final products. Intel puts this improvement in frequency down to its new SuperFin transistor design and updated manufacturing process.
When it comes to clock-for-clock raw performance gains for Tiger Lake, the differences compared to Ice Lake are not as clear cut, primarily because the cores microarchitecture layout between the two only has a few small changes. We’ll cover those a bit later.
What is 10nm SuperFin All About?
For those within the semiconductor industry, as well as individuals with investments in the companies we cover, it has been hard to miss the recent news surrounding Intel’s manufacturing process woes. In short, Intel’s 10nm process technology has failed to match expectations in performance and yield, coming in a couple of years later than expected and with an inability to compete with its own previous generation products. It still remains in low volume today, with Tiger Lake expected to be the first true example of what Intel’s vision 10nm was meant to be.
The next step function change in Intel’s manufacturing, the move to 7nm using Extreme Ultra Violet (EUV) technology, has recently been announced that it also has an additional six month delay. With news like this, it has become a struggle to remain confident about Intel’s ability to deliver an industry-leading manufacturing node technology that is competitive in the market. This used to be the position that Intel held until delays crept into the 10nm process.
Intel’s Ruth Brain, Senior Transistor Architect, Covering Intel’s Engineering Feats
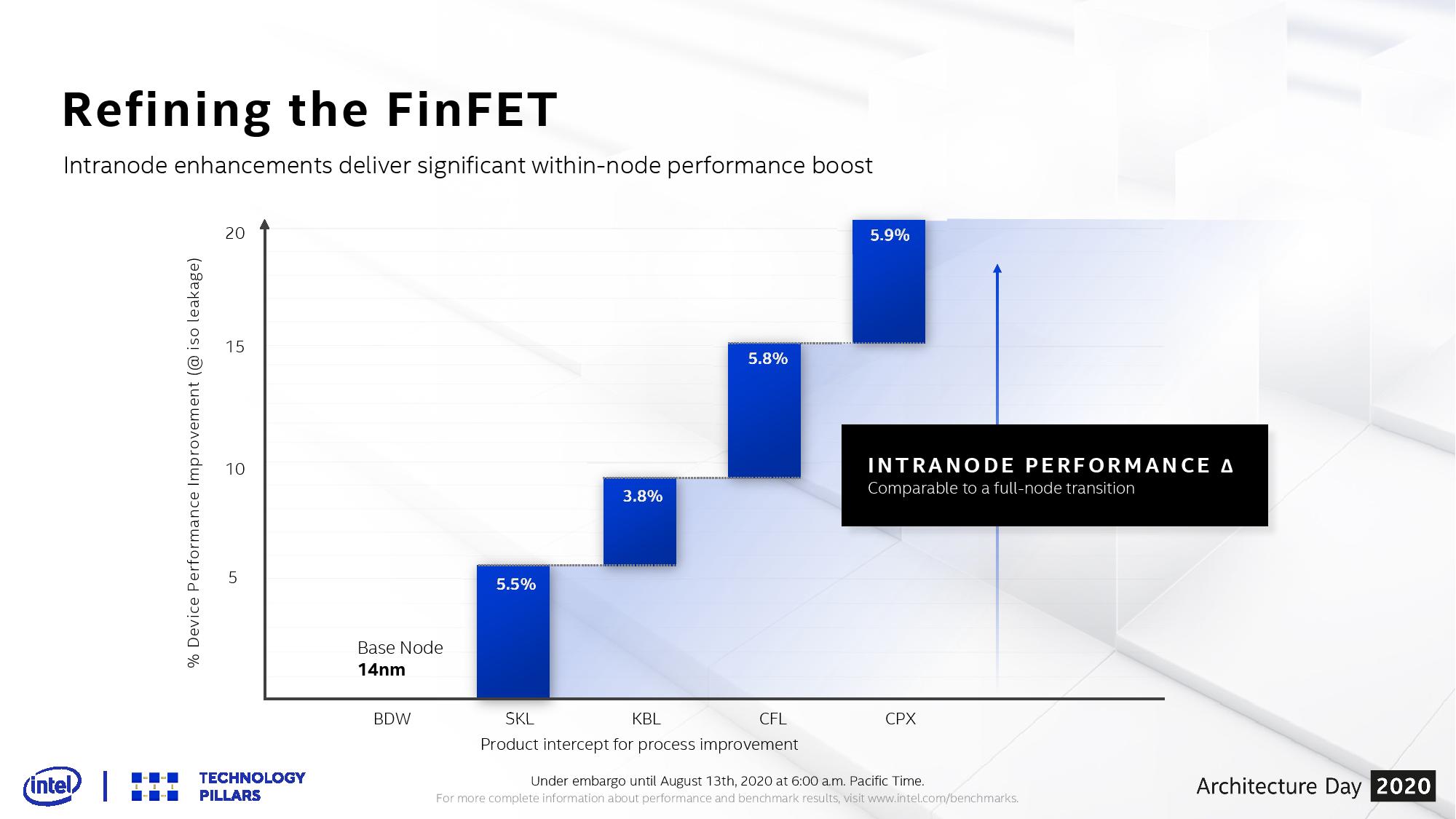
Intel’s disclosures on its manufacturing technology vary in complexity depending on how successful the product is perceived internally. When Intel first announced FinFETs on its 22nm process node, in May 2011, there was a lot of information straight out of the gate, and the node was very successful. With the next generation of 14nm, there were some delays with the initial generation of Broadwell products, but ultimately the process was explained in detail by the company at its own event and we published our article on 14nm in August 2014. The 14nm process node has been Intel’s most profitable manufacturing node to date, and continuous intranode enhancements over the years (14+, 14++, 14+++, 14++++*) have given the company an effective enhancement equivalent to a pure node update within a manufacturing generation.

*Yes, Intel has a 14++++ node. It’s even in their diagrams. The only product confirmed to be on 14++++ as far as we can tell is the Cooper Lake Xeon Scalable family.
When it comes to 10nm, the situation is not as rosy, even compared to the delays on 14nm. To date, Intel has had two generations of 10nm products on the CPU side, one of which the company steers away from even trying to mention it in public, even though we’ve reviewed it in excruciating detail.
Cannon Lake, the first 10nm product, found its way into Intel’s Crimson Canyon NUC mini-PCs and was a hot mess: two cores only, disabled integrated graphics, and although it shipped for revenue in 2017, Intel was right to consign it to history very quickly.
Ice Lake was Intel’s proper launch vehicle for 10nm, offering four cores and a lot of Gen11 graphics within 15 watts. It has found its way into over 50 laptop designs, but as mentioned on the previous page, despite its 15-20% increase in raw performance clock-for-clock, that 10-20% decrease in frequency balances it out for a minimal CPU improvement over 14nm. The graphics on Ice Lake are still a lot better than on 14nm, and support for Thunderbolt 3 as well as 512-bit vector instructions means that Ice Lake still has a few plus points.
As it stands, because Intel doesn’t want to consider Cannon Lake as a true part of its heritage, Ice Lake was deemed a flat ‘10nm’ product, with no plusses and no extra bits. After Ice Lake was set to be Tiger Lake, built on a ‘10+’ manufacturing node.
+, ++, +++, ++++: What is a Name
A side note about manufacturing process naming. As many of our readers are aware, the actual number attached to the process in the era of FinFET technology has effectively become nothing more than a proper noun for the process node technology – it isn’t related to any feature within the products built on that process. It gets especially confusing when there are features of a process built at a smaller scale than the number on the technology: for example, Intel’s 10nm actually has features that are 8nm in size. Manufacturing nodes might as well be given names like Gordon, Eric, or Lisa, in order to stop the confusion that having that number provides.
Within a generation of a process node technology, the company fabricating the semiconductor orders may periodically update its manufacturing process but still keep it, by and large, within the confines of that generation. These updates are often minor, but are called BKM (best-known-method) updates and can lead to simple frequency or power efficiency improvements – perhaps on the order of 50 mV or 25 MHz, but sometimes afford bigger gains.
When we were dealing with planar transistors, at 22nm, 32nm, 45nm and above, these BKM updates were par for the course during the lifecycle of a product built at that node. Improvements in the manufacturing were taken, rolled into the product automatically, and it was simply sold in the same box without much of a fuss, but had marginally better characteristics.
As we’ve moved into multiple generations of FinFET technologies, where creating a leading edge high-performance processor can cost $10-$100million or more, these BKM updates have become marketable updates to both the chip design companies and the fabs they are built on. Small tweaks to the BKM are now being used to launch new waves of products, and offer the companies involved a chance to create column inches and highlight the engineering prowess of the teams involved, as well as offering the customer a better product.
Different fabrication plants have marketed these updates in different ways. Intel has gone with the +,++,+++,++++ nomenclature for its 14nm process, with each step giving better transistor device performance and being rolled into new generations of products:
However, Intel’s naming scheme has become somewhat of a meme and a joke over the past few years. With the company’s inability to bring out 10nm on its initial schedule, Intel decided to add more + to each new process update on 14nm. As 10nm was delayed further, consumers and users saw another + added to 14nm. The meme of Intel unable to get 10nm working and seeing a 14+++++++++ future product is a fundamental strike to the soul of a company that has spent the last 30+ years priding itself on its ability to drive leading edge semiconductor manufacturing for high-performance.
As Intel has slowly moved onto its 10nm product portfolio, the + naming came in again almost immediately. 10nm for Cannon Lake, 10+ for Ice Lake which later became just ‘10nm’, 10+ for Tiger Lake, and then 10++ and 10+++ were all exhibited on roadmaps at various industry events. The same story goes on for future processes, such as 7nm and 5nm.

If it makes you feel any better, Intel’s own engineers said that even they sometimes have difficulty remembering which + variant has specific updates, or which product is built on which + node. Ultimately, while the + serves a purpose, it has ultimately become confusing for customers and engineers alike.
This is why, behind the scenes, we have told Intel that it has to move away from + and ++ and +++, if only from a corporate image standpoint. Where its manufacturing competitors like TSMC and Samsung can point to different variants of their 10nm processes for different products, all Intel has is more pluses.
Other press and analysts have told Intel this too. However, based on previous experiences, we rarely get to speak to the people who actually can cause direct change. All our contacts can do is try, and pass our comments up the chain, hopefully with as much passion as we have. The people that can actually sign off on changes like this are often not very press facing.
But someone, somewhere at Intel, has finally heard our pleas. Today Intel is approaching its 10nm portfolio from a different angle. While nothing is technically changed under the hood, the new strategy allows the company to market its manufacturing and products from an initial context of the deep engineering portfolio and research that occurs. The first result of this change is the SuperFin.
Intel 10SF: The Largest Single Intranode Enhancement in Intel History
10nm SuperFin is what Tiger Lake is built on, and represents the new name for 10+. As part of Intel’s 10SF, we’re getting a glimpse into what makes 10SF different to the 10 for Ice Lake , as well as updates on some key parts to the design of the transistors and metal stack that make up the 10SF process.

10SF builds on 10nm by introducing a redefined FinFET design (Intel’s 4th Gen FinFET?) with increased Fin performance, as well as a new SuperMIM (metal-insulator-metal) capacitor design.
The updated FinFET design focuses on three areas.

Through new manufacturing techniques, the epitaxial growth of crystal structures on the source and drain has been enhanced, ultimately increasing the strain in order to lower the resistance allowing more current to flow through the channel.
An enhanced source/drain architecture and improved gate manufacturing process helps drive additional higher channel mobility, which enabling charge carriers to move more quickly and improves transistor performance.
Additionally a larger gate pitch to enable higher drive current for certain chip functions that require the most performance. Normally a larger gate pitch sounds the opposite of what we want for a dense process node technology, however it was explained that in this case making the transistor bigger with improved performance actually means that fewer buffers are needed in the high performance cell libraries, and ultimately the cell size decreases as a result. Note that on some of Intel’s 14nm variants, one of the techniques used to help drive higher frequency was a larger gate pitch.
For the metal stack, Intel makes some very bold claims with impressive technology.

At the lower layers of the stack, Intel is introducing a new set of barrier materials to enable thinner barriers, which also helps reduce resistance of vias by up to 30% by enabling the metal each via to be a bigger proportion of the fixed size. Reducing the resistance enhances the performance of the interconnect between the metal layers
At the higher levels, Intel is introducing a new SuperMIM (metal-insulator-metal) capacitor. Intel states that this new design gives a 5x increase in capacitance over an industry standard MIM cap within the same footprint. This drives a voltage reduction that ultimately leads to drastically improved product and transistor performance. Intel states that this is an industry first/leading design, enabled through careful deposition of new Hi-K materials in thin layers, smaller than 0.1nm, to form a superlattice between two or more material types.
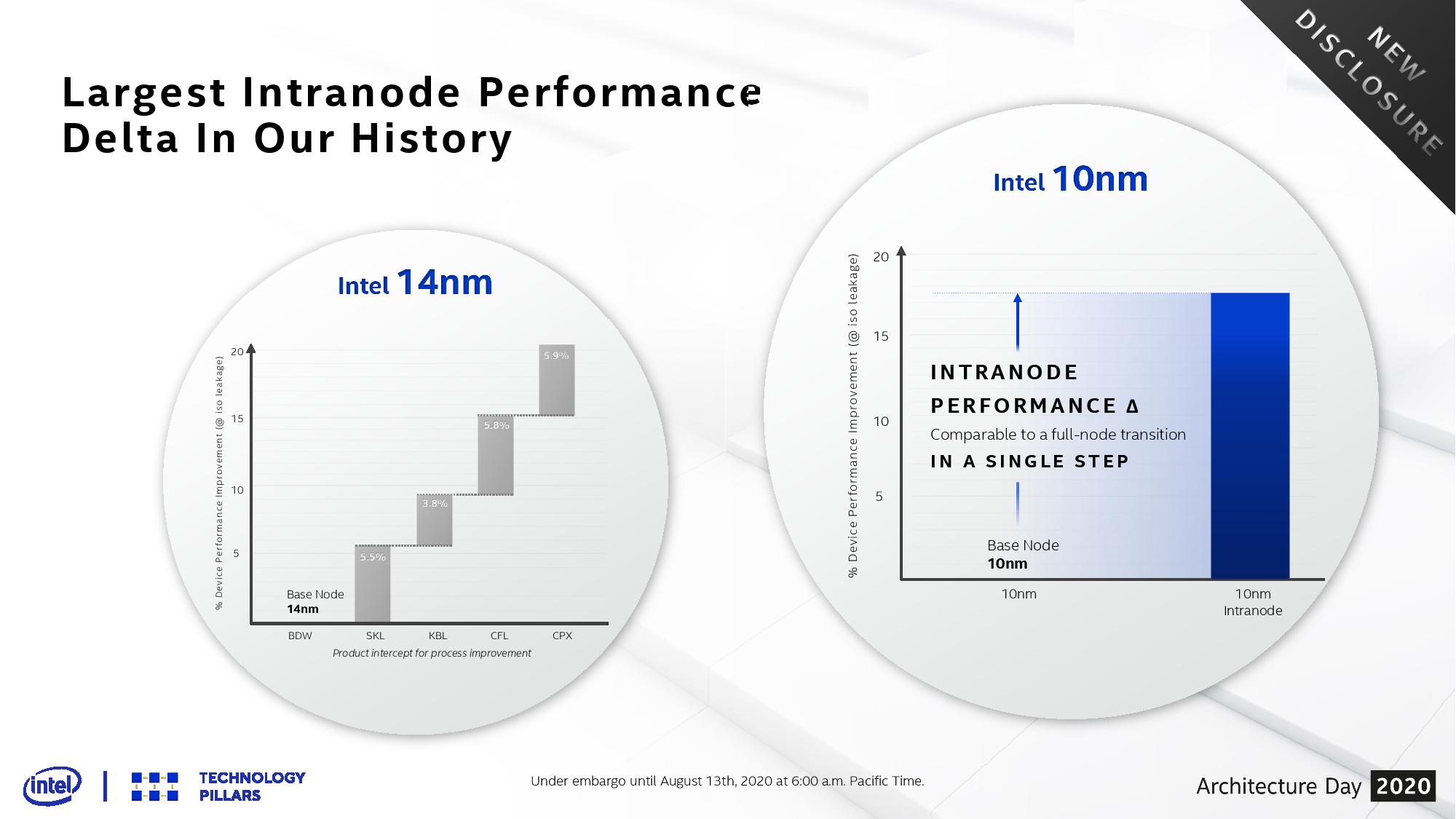
All combined, Intel’s Senior Transistor Architect, Ruth Brain, states that these features enable the ‘Largest single (intra)node enhancement in Intel history’, enabling 17-18% better transistor performance from the base 10nm designs. This makes 10SF equivalent to a full node enhancement over Intel’s base 10nm process. To draw parallels to Intel’s 14nm, 10SF to 10 is the equivalent of Coffee Lake (14+++) to Broadwell (14nm).
Beyond SuperFin to Enhanced SuperFin
As part of Architecture Day 2020, Intel also stated that the intranode update beyond 10SF will be called 10ESF, or 10 Enhanced SuperFin. No specific details were given as to what 10ESF will provide over 10SF, only that it will bring additional performance and interconnect innovations.
That being said, Intel stated that it would be optimized for the datacenter, which likely means that some characteristics will be changed in order to support the increased thermal and current density that comes with vector acceleration. Intel, perhaps accidentally, confirmed to us that there will be three products based on 10ESF.
| Products using Intel 10SF and 10ESF | |
| 10SF | Tiger Lake Xe-LP (SG1, DG1) Xe-HPC Ponte Vecchio Active Interposer Tile |
| 10SFE | Xe-HP Xe-HPC Ponte Vecchio Rambo Cache Tile Sapphire Rapids |
(Intel has stated that Ponte Vecchio will have four types of tile: base, compute, Rambo Cache, and Xe Link. The others not mentioned will be split between 7nm and external fabs. More on that info in a separate article)
What is in a Willow Cove Core?
At Intel’s Architecture Day 2018, the company showcased its new CPU core roadmap covering the next several generations of both the high performance cores and the high efficiency cores. Intel updated the slide for the new event.
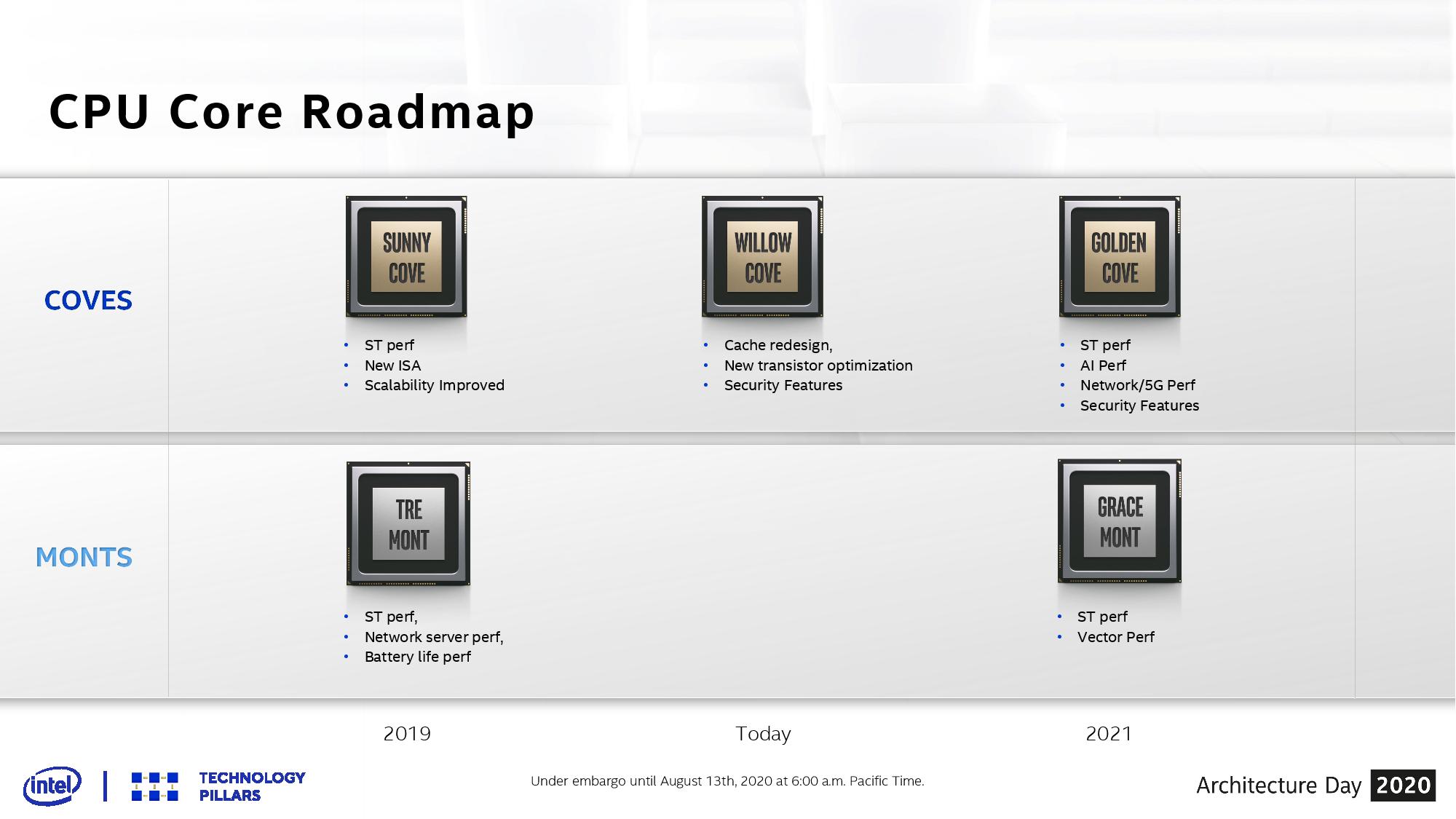
Not so much new has been added, however it is worth covering.
On the top we have the Cove cores, which represent Intel’s high performance designs. It starts with Sunny Cove as the 2019 core, which we can find inside Intel’s Ice Lake and Lakefield processors today. Sunny Cove was set to provide an increase in single threaded performance (we saw 15-20% clock-for-clock), a new set of instructions (VNNI for deep learning), and scalability improvements.
In the middle for the Cove section is Willow Cove, which forms the fundamental compute core for Tiger Lake. On this slide it shows that Willow Cove has a cache redesign (see below), a new transistor optimization (see previous page), and implements new security features.
The 2021 high performance core will be Golden Cove, which Intel states will offer another jump in single threaded performance, more AI performance, and offer performance related to networking and 5G.
Then there’s also some Monts, which are the efficiency-focused Atom cores. We did an analysis of Tremont’s microarchitecture, which you can read here. Gracemont in 2021 will be the Atom core built for Intel’s next generation Hybrid CPU architectures.
Willow Cove: +10-20% Performance Over Sunny Cove
The story of Willow Cove is going to be a bit confusing for a lot of people. It certainly was to me when it was first explained. But I’m going to rip the band-aid off quickly for you, just to get it over and done with.
The microarchitecture of a Willow Cove core is almost identical to that of a Sunny Cove core.
It is almost a copy-paste, but with three key differences that enable a 10-20% performance uplift over Sunny Cove. As it stands, there is no point drawing a diagram to explain the front-end and the back-end of Willow Cove. I suggest you read our deep dive into Sunny Cove, because it’s going to be the same in pretty much all areas. Same branch predictors and decode, same re-order buffers and TLBs, same execution ports, same reservation stations, same load/store capabilities.
Moving the core from Sunny Cove to Willow Cove affords only three differences that need to be highlighted. There is an additional change within the memory subsystem that will be addressed here also.
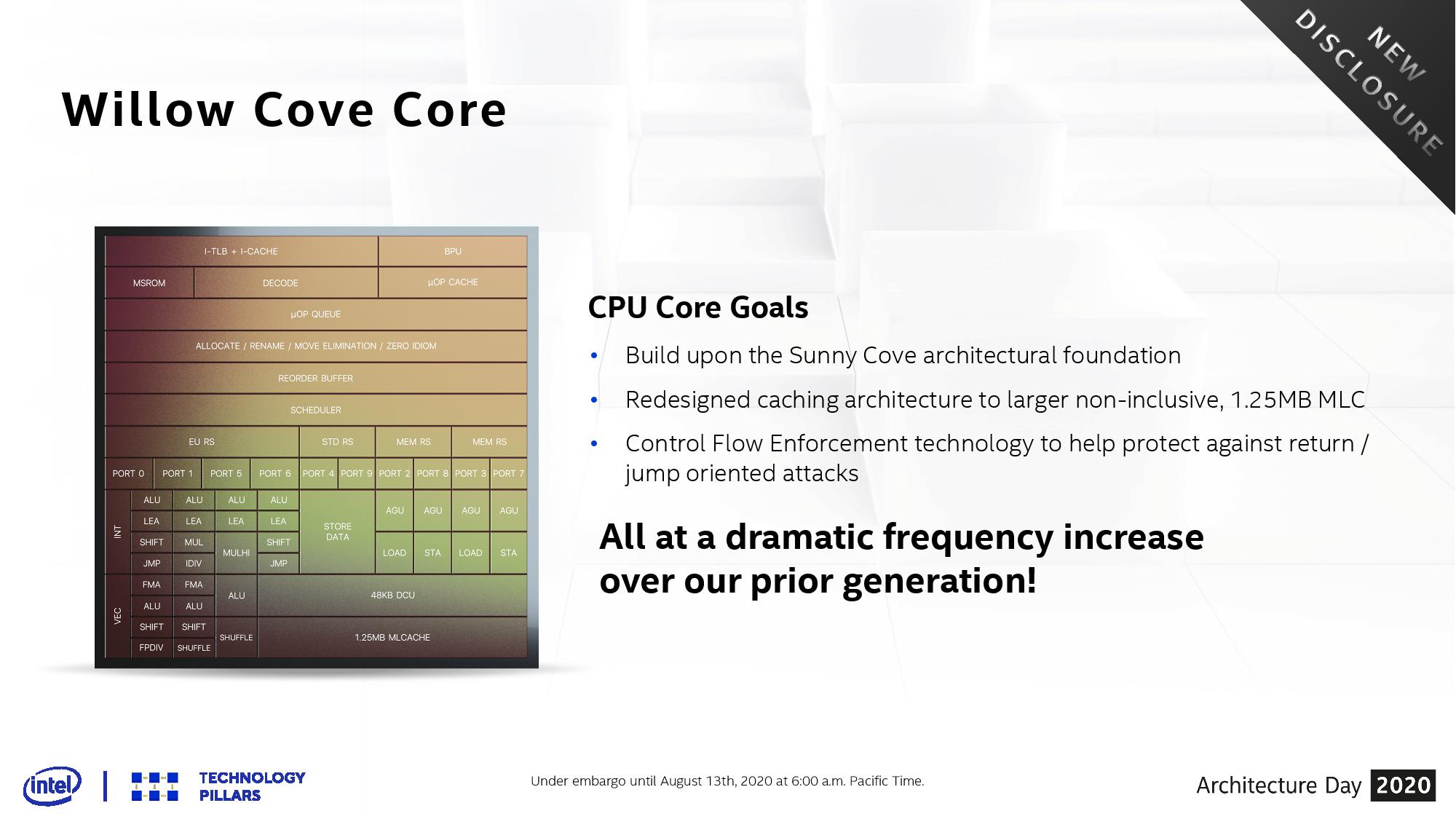
SuperFin Frequency
First, where most of the performance uplift comes from, is the process node. Moving to 10SF and the new SuperFin transistor has enabled Willow Cove to scale better with respect to voltage and frequency, allowing for better metrics across the board. This means better performance at the same voltage, or the same performance at a lower voltage, compared to Sunny Cove. Where the +10-20% performance comes from is at the high-end. Where Sunny Cove was limited to a peak frequency around 4.0 GHz, Willow Cove appears to promise something more akin to 5.0 GHz.
This is Intel’s slide showing this, however at present the company isn’t giving any hard numbers to act as reference points here. We could be talking anything from 10 mV to 100mV or more savings at active frequencies, or not. The only thing that looks eminently readable is that peak frequency. At the same peak voltage as Sunny Cove we see more of a +500 MHz gain for Willow Cove, but it requires more voltage to get to that other peak nearer 5.0 GHz, which obviously would mean higher power consumption.
Bearing in mind that the PL2 values (peak turbo power consumption) for Ice Lake were essentially 50 W when all cores were loaded with AVX-512, this means we could be looking closer to 65 watts for Tiger Lake. Intel at one point did mention that this version of Tiger Lake was supposed to scale from 10 W to 65 W, but despite repeated questioning the company failed to elaborate on what product the ’65 W’ metric would come into play.
More L2 and L3 Cache
The second update to Willow Cove is the cache structure. Intel has boosted the size of both the L2 and L3 cache within the core, however as always with cache sizes, there are trade-offs worth noting.
The private L2 cache gets the biggest update. What used to be an inclusive 512 KiB 8-way L2 cache on Sunny Cove is now a non-inclusive 1.25 MiB 20-way L2 cache. This represents a +150% increase in size, however at the expense of inclusivity. Traditionally increasing the cache size by double will decrease the miss rate by √2, so the 2.5x increase should reduce L2 cache misses by ~58%. The flip side of this is that larger caches often have longer access latencies, so we would expect the new L2 to be slightly slower. Intel declined to give us the new value.
For the L2, there is also an extra small performance gain as non-inclusive caches do not require back-invalidation. However, moving to a non-inclusive cache has a knock-on effect to die area and power. In Intel’s previous architectures, the L2 cache was inclusive of the L1 cache, which meant that every cache line found inside the L1 had an identical copy in the L2. With a non-inclusive cache, extra hardware has to be built into the core in order to satisfy cache coherence rules. It is worth noting that as early as 2010, Intel has been presenting at conferences that it can build inclusive caches that run at the speed of non-inclusive caches; perhaps this does not hold true any longer as cache size is increasing.
As for the L3 cache on a quad-core Willow Cove system, Intel has moved from an 8 MiB non-inclusive shared L3 cache to a 12 MiB shared L3 cache. This is a +50% increase in capacity, however Intel has reduced the associativity, from a 16-way 8 MiB cache to a 12-way 12 MiB cache. The effect of the two on performance is likely to be balanced.
| Cache Comparison | |||||
| AnandTech | Coffee Lake 4C |
Ice Lake 4C |
Tiger Lake 4C |
AMD Zen2 4C |
|
| L1-I | 32 KiB 8-way |
32 KiB 8-way |
32 KiB 8-way |
32 KiB 8-way |
|
| L1-D | 32 KiB 8-way 4-cycle |
48 KiB 12-way 5-cycle |
48 KiB 12-way 5-cycle |
32 KiB 8-way 4-cycle |
|
| L2 | 256 KiB 4-way 12-cycle Inclusive |
512 KiB 8-way 13-cycle Inclusive |
1.25 MiB 20-way ? Non-Inclusive |
512 KiB 8-way 12-cycle Inclusive |
|
| L3 | 8 MiB 16-way 42-cycle Inclusive |
8 MiB 16-way 36-cycle Inclusive |
12 MiB 12-way ? Non-Inclusive |
16 MiB 16-way 34-cycle Non-Inclusive |
|
Overall IPC gains in the core due to this increase are expected to be low single digits. A lot of these features are ultimately an exercise in tuning – increasing one thing to get better throughput might cause extra latency and such. An interesting question will be how these cache changes have had an effect when it comes to die area (is the core bigger?) or power (can the core go into lower power states?). The new SuperFin transistor may also allow Intel to create denser caches, and this is taking advantage of that.
Security and Control-Flow Enforcement Technology
Another aspect of recent news is Intel’s security, and given the life cycle of modern leading edge processors, trying to predict security needs of a future product is often difficult. With every generation and silicon spin, Intel has been plugging security holes as well as enabling more elements to enhance security both for targeted attacks and at a holistic level.
Willow Cove will now enable Control-Flow Enforcement Technology (CET) to protect against return/jump oriented attacks that can potentially divert the instruction stream to undesired code. CET is supported in Willow Cove through enabling Shadow Stacks for return address protection through page tracking. Indirect Branch Tracking is added to defend against misdirected jump/call targets, but requires software to be built with new instructions.
The Memory Subsystem: More Bandwidth, LPDDR5 Support
While not strictly speaking part of the Willow Cove core, with respect to the Tiger Lake SoC, the new memory subsystem will also have an effect on performance. Much like Ice Lake, Tiger Lake will support both up to 64 GB DDR4-3200 or 32 GBLPDDR4X-4266, enabling 51.2 GB/s or 62.8 GB/s of bandwidth respectively, however Tiger Lake also supports 32 GB of LPDDR5-5400 memory for an impressive memory bandwidth increase to 86.4 GB/s.
LPDDR5 is the latest new technology for mobile memory subsystems, and we are told that Tiger Lake will support this out of the box, however it will be up to Intel’s OEM partners to use it in their Tiger Lake systems. At present, we are told that the cost of LPDDR5 is too high for consumer products, so we’re likely to see DDR4/LP4 systems to begin with. The cost of LP5 will come down as manufacturing ramps up and demand increases, however those systems might be later in the Tiger Lake life cycle.
It is worth noting that the Tiger Lake SoC has doubled up to support a dual-ring bi-directional interconnect which allows for 2x32 B/cycle in either direction. This helps the memory controllers to feed the cores as well as the graphics, so we should see some uplift in performance on memory-limited scenarios. One question to ask Intel is why have they gone for a dual ring design, rather than simply making a single ring double-wide – the answer is likely related to sleep state power, if one ring can be put to sleep as required. The trade off to that would be related to control and die area, however.
Total Memory Encryption
Tiger Lake’s Memory system also supports full Total Memory Encryption. TME has been a popular feature of new silicon designs of late, and enables mobile device users to have the data held in the memory on a system physically secure against hardware attacks. In other systems we’ve been told that a feature like TME, when implemented correctly, only gives a 1-2% performance hit in the most usual worst case – Intel has not provided equivalent numbers as of yet. Given the type of feature this is, we suspect TME might be more of a vPro-enabled product feature, however we will have to get clarity on that.
What is Xe-LP?
A big part of the Tiger Lake/Ice Lake comparison will be the performance difference in graphics. Where Ice Lake has 64 Execution Units of Gen11 graphics, Tiger Lake has 96 Execution Units but of the new Xe-LP architecture. On top of that, there’s the new SuperFin transistor stack that promises to drive frequencies (and power windows) a lot higher, making Tiger Lake more scalable than before.
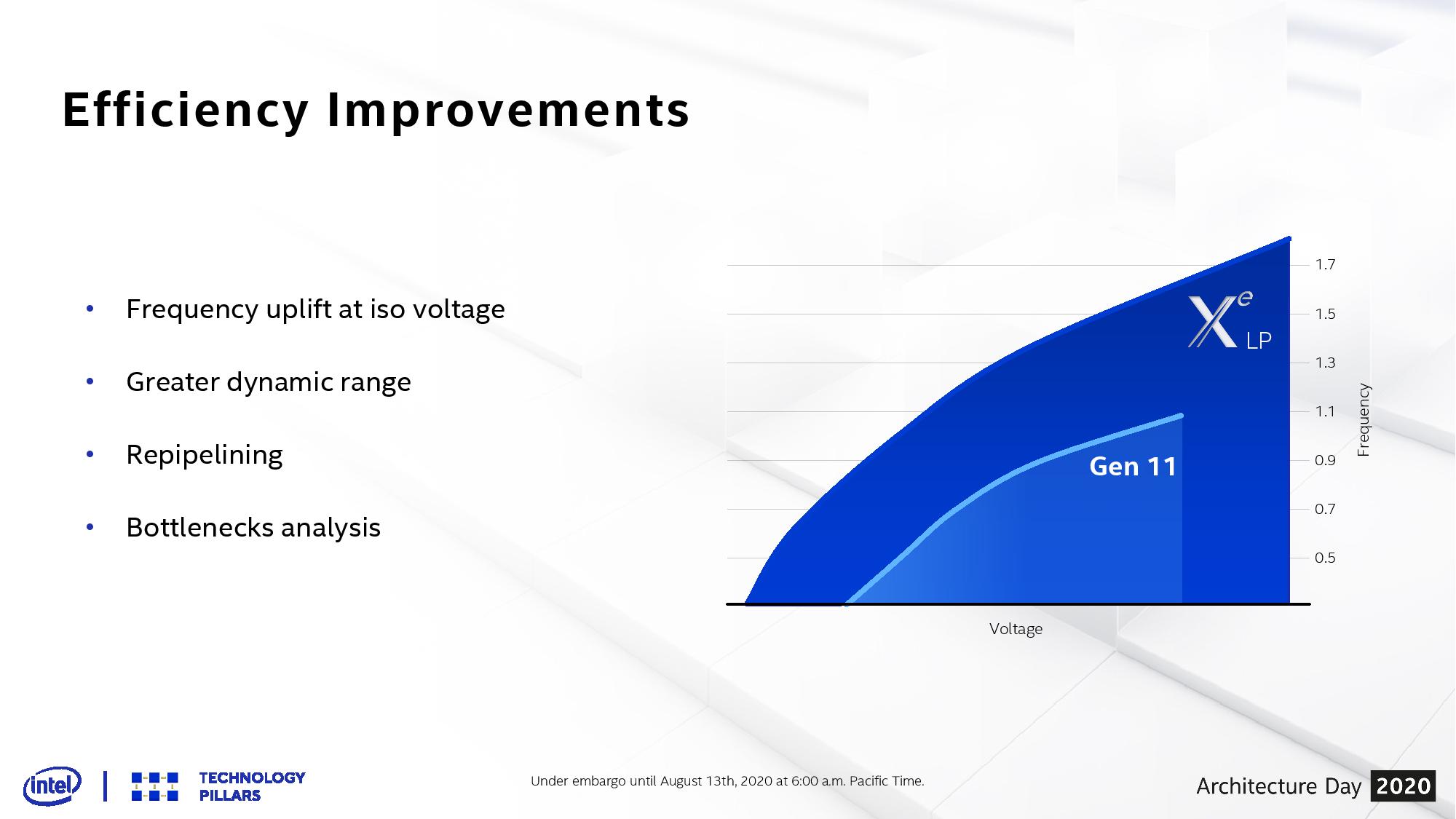
Straight off the bat Intel’s graphs are showing that at the same voltage, where Ice Lake Gen11 achieves 1100 MHz, the new Xe-LP graphics will get to ~1650 MHz, a raw +50% increase. That means at Ice Lake’s peak power, we should expect Tiger Lake to perform at a minimum 2.25x better. Expanding beyond that, the peak for Tiger Lake seems to be in the 1800 MHz range, ultimately giving a minimum 2.45x more performance over Ice Lake. This is before we even start talking about the fundamental differences in the Xe-LP architecture compared to Gen11.
Intel is promoting Xe-LP as operating at 2x the performance of Gen11, so even though these numbers might easily suggest a 2.25x uplift before taking into account the architecture, it will ultimately depend on how the graphics is used.
Gen11 vs Xe-LP
For a more in-depth look into Intel’s Xe graphics portfolio, including HP, HPC, and the new gaming architecture HPG, Ryan has written an article covering Xe in greater detail. In this article, we’ll cover the basics.
In the Ice Lake Gen11 graphics system, each one of the 64 execution units consisted of two four-wide ALUs, one set of four for FP/INT, and the other set of four for FP/Extended Math. 16 of these execution units would form a sub-slide within Gen11.

For Xe-LP, that 4+4 per execution unit has been rebalanced for this target market. There are now 10 ALUs per execution unit, but in an 8+2 configuration. The 8 ALUs support 2xINT16 and INT32 data types, but also with new DP4a instructions can accelerate INT8 inference workloads. The new execution units also now work in pairs – two EUs will share a single thread control block to help assist with coordinated workload dispatch.
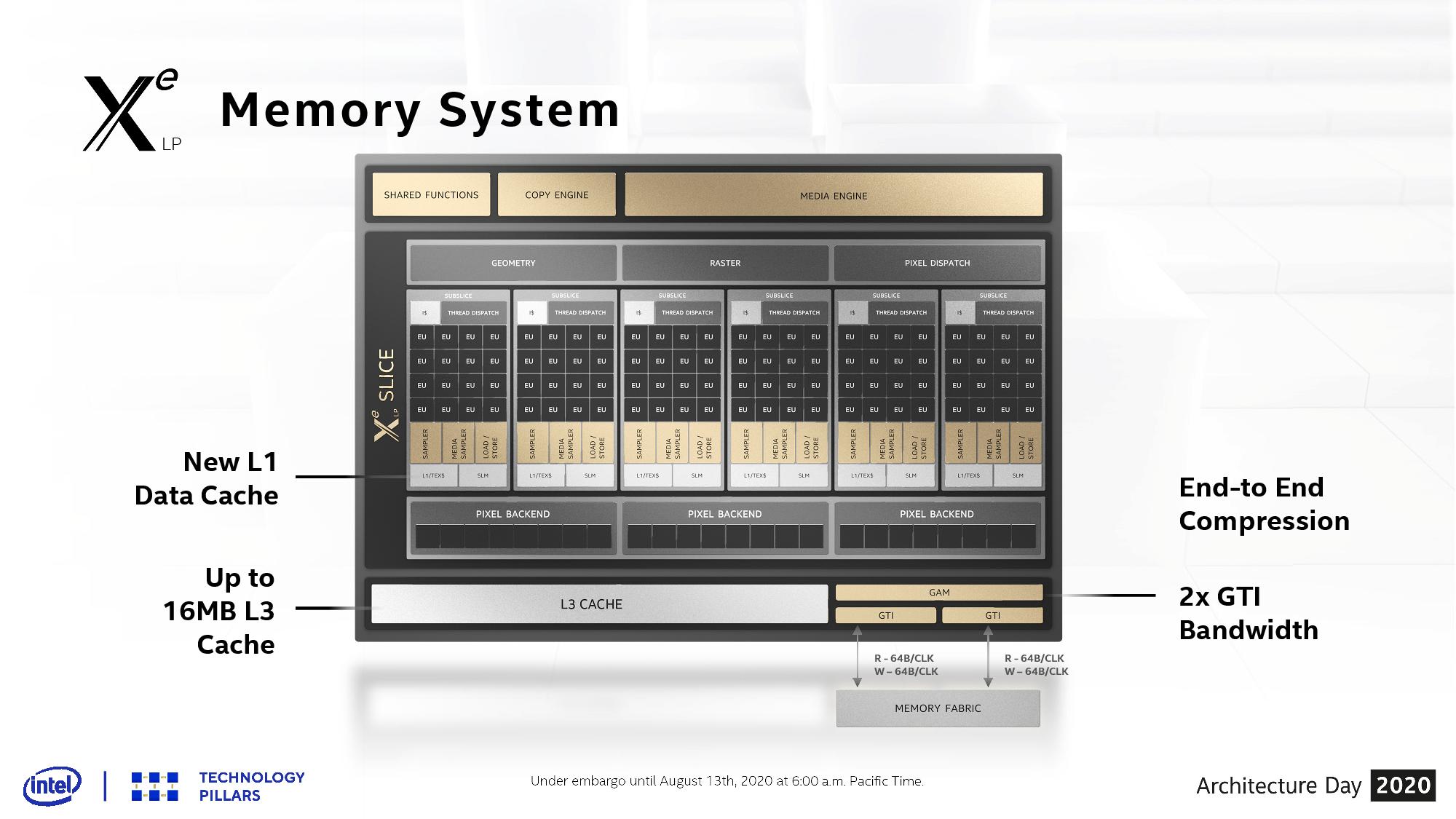
As with ICL, 16 of the EUs now form a sub-slice with the graphics, and slices are added in the SoC as performance is needed. What is new in Tiger Lake is that each sub-slice now has its own L1 data and texture cache, and the pixel backend runs 8 pixels/clock per two sub-slices.
Overall the graphics system can support 1536 FLOP/clock, with the samplers at 48 Tex/clock per sub-slice and a total of 24 pixel/clock in the back-end. LP in Tiger Lake has 16 MiB of its own L3 cache, separate from the rest of the L3 cache in the chip, and the interface to the memory fabric is doubled, supporting 2x64B/clock reads or writes or a combination of both.
Exact performance numbers for Xe-LP in Tiger Lake are going to be a question mark until we get closer to launch. Intel has stated that the discrete graphics version of LP, known as DG1, is due out later this year.
Xe-LP Media and Display
The other question on Tiger Lake on graphics will be the media and display support. Tiger Lake will be Intel’s first official support for the AV1 codec in decode mode, and Intel has also doubled its encode/decode throughput for other popular codecs. This means a full hardware-based 12-bit video pipeline for HDR and 8K60 playback support.
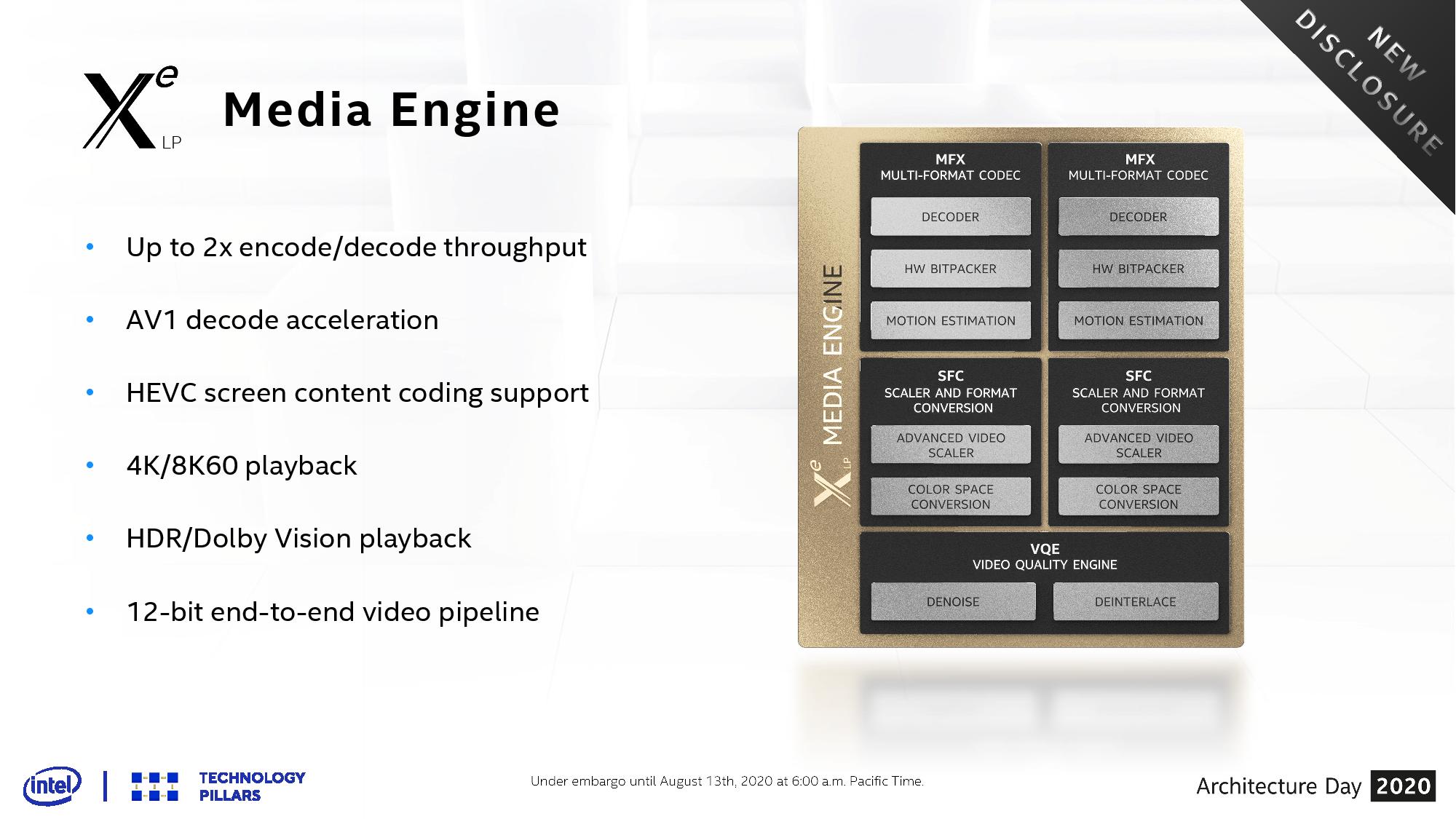
Display Support for Tiger Lake is also extended with four 4K display pipelines. Connections over DP1.4, HDMI 2.0, Thunderbolt 4, and USB4 Type-C simultaneously is how Intel expects users to operate if all four outputs are needed at once. The display engine also supports HDR10, 12-bit BT2020 color, Adaptive Sync, and support for monitors up to 360 Hz.

External Graphics and Hybrid Support
One of the interesting questions we posted to Intel during Architecture Day was surrounding how Xe-LP will operate in the presence of additional graphics, and potentially paired with a discrete version of LP later in the year. Unfortunately there seemed to be some confusion between the definitions of ‘hybrid’ graphics vs ‘switchable’ graphics, so we got that cleared up in time for the article.
At present, Intel expects almost all Tiger Lake solutions to run in devices where there is no discrete graphics solution – only the integrated graphics is provided as the primary compute for gaming and acceleration. However, Tiger Lake will support switchable graphics solutions with Xe-LP discrete graphics. Intel did not state if this was discrete graphics with respect to a built LP chip or an external discrete graphics solution through Thunderbolt.
Due to Tiger Lake’s PCIe 4.0 support and Thunderbolt 4 support, depending on how an exact Tiger Lake system is configured, Intel expects that any discrete graphics solution will operate at a lower latency, mostly due to the fact that the PCIe 4.0 lanes will be directly attached to the CPU, rather than a chipset. Intel quoted ~100 nanosecond lower latency. They also stated an 8 GB/s bandwidth to main memory, which seemed a bit low?
On the topic of hybrid graphics, where the integrated graphics and an Xe-LP discrete solution could work in tandem on the same rendering task, Intel stated that there is no plan to support a Multi-GPU solution of this configuration.
Tiger Lake IO and Power
As part of Tiger Lake, other enhancements have been made to the chip outside of the traditional CPU/GPU components. In this article, as they directly impact core performance, we’ve already discussed improvements to the fabric, enabling a doubling of bandwidth with the dual bidirectional ring design, and the new LPDDR5-5400 support on the memory controller – go back a couple of pages to find information on these.
PCIe 4.0 Support
We lightly touched upon it in the graphics section, but the four core Tiger Lake processor will be the first mobile processor to support PCIe 4.0 directly from the CPU. Intel hasn’t specifically stated how many lanes of PCIe 4.0 the processor will support, which is kind of frustrating at this time, but they have made it clear that they have not experienced a power penalty moving from PCIe 3.0 in Ice Lake to PCIe 4.0 in Tiger Lake.
As it stands, Intel expects the PCIe 4.0 lanes to be used in these mobile processors primarily for PCIe 4.0 storage, however given the status of the current PCIe 4.0 NVMe SSDs on the market today and the high power requirements of the Phison E16 controller (~8W), we might have to wait a bit for other controllers to come in volume.
Intel did state that the quantity of PCIe 4.0 lanes did have a direct correlation with the CPU count and the power of the chip, but refused to state what the scaling is. Based on comments made by Intel during the Architecture Day, such as Tiger Lake supporting 24 MiB of L3 cache which would require an 8-core CPU, we suspect that a full 16 PCIe 4.0 lane version (or more?) to align with that product instead. That would mean the 4-core Tiger Lake version would be more akin to an 8-lane processor, which would gel with what we’ve seen with other mobile processors in the past.
However, there is part of me that suspects that this processor has only four PCIe 4.0 lanes. Intel’s quote about remaining iso-power between Ice Lake (PCIe 3.0 x8) and Tiger Lake on PCIe 4.0 might actually be that tradeoff – moving down to four lanes keeps that iso-power. Even with four PCIe 4.0 lanes, that’s still enough for a discrete Thunderbolt graphics card and a super-fast NVMe SSD, or dual NVMe 4.0 x2 drives. The higher data rates on PCIe 4.0 do require more power per lane, assuming an iso-process, as we’ve presumed with other products, but there are always silicon improvements that might help with that.
Update: Another element to support the PCIe 4.0 x4 theory – in multiple places during Architecture Day, Intel states that devices accessing memory over PCIe will have ‘8 GB/s bandwidth. Each PCIe 4.0 x1 link is approx. ~2 GB/sec, which would imply there is only four.
Gaussian and Neural Accelerator 2.0 (GNA)
One of the accelerators that Intel offered in Ice Lake was the GNA - a simple low power inferencing engine that enables the system to offload basic analysis or workloads such as noise reduction for calls or voice recording. In a previous guise, the GNA built upon the Gaussian Mixture Model, which we believe was IP dedicated to accelerating Microsoft’s Cortana in voice recognition. With Tiger Lake, we now get GNA 2.0.

No specifics were necessarily given as to what has changed this time around, aside from having the benefits of the 10SF process technology. Intel did quote some handy numbers though, stating that GNA 2.0 can perform 1 GigaOP at 1 milliwatt, and this can scale linearly up to 38 GigaOPs for 38 milliwatts. Intel never released similar performance/efficiency numbers for Ice Lake, stating only that GNA 2.0 is ‘enhanced’ for Tiger Lake.
Display and Image Processing Unit
We’ve covered the Display aspects of the Tiger Lake in the graphics section, but to reiterate, there are four 4K display pipelines: DP1.4, HDMI 2.0, Thunderbolt 4, and USB4 Type-C can be used simultaneously. The display engine also supports HDR10, 12-bit BT2020 color, Adaptive Sync, and support for monitors up to 360 Hz, and Intel states that the display engine can support up to 64 GB/s to memory, suggesting there is some overhead or bottleneck compared to the 86.4 GB/s supported by LPDDR5-5400. Tiger Lake also supports direct-to-memory data transfer for the display engine, bypassing the CPU – a feature first introduced with Skylake.

For the image processing unit, Intel has used the 10SF transistor budget to increase the size of its imagine pipelines in hardware. There is still support for six cameras, the same as Ice Lake, but the Tiger Lake silicon will eventually be capable of 4K90 video and 42 MP imaging support. Notice the ‘will eventually be capable’ in that last sentence – Intel has specified that this four core Tiger Lake will only support 4K30 and 27MP for video and imaging respectively. It wasn’t clarified at the time why there was this discrepancy and what it means, but our best guess is one of two things: the larger 8-core version of Tiger Lake (the one with the 24 MiB L3 cache that Intel kept talking about) will have the full support, or the full support can only be enabled with faster memory such as LPDDR5-5400, which won’t be available until mid-way through Tiger Lake’s product cycle.
Thunderbolt 4
Tiger Lake will be Intel’s first deployment of Thunderbolt 4 hardware, and the company will follow up with TB4 controllers for non-TGL systems later this year. TB4 is a superset of the USB4 standard, and thus Tiger Lake will also support USB 4. The way the Tiger Lake chip is built, two Thunderbolt 4 ports will be supported on each side of the laptop, and each port will support the full 40 Gb/s bandwidth. In order to qualify for next generation Athena specifications, one of those will need to be a quick-charging port.

We covered Thunderbolt 4 a few weeks ago, as Intel wanted to discuss TB4 ahead of the Tiger Lake launch. One of the key requirements for TB4 certification is that the processor must support some form of DMA write protection to prevent physical attacks. Intel does this through its processors supporting VT-d instructions, and when TB4 controllers come out, other processor vendors will have to enable similar technologies. Another TB4 certification requirement is going to be supporting wake-from-sleep through any TB4 device, such as a dock.
Power Management and Frequency/Voltage Scaling
One of the most important drivers with mobile processors is idle and sleep power – the more parts of the chip that can be put into a low power state when not in use, the better the battery life.
At a high level this means that if a laptop is playing a video, on the CPU we have the display engine is on and the video decode on, but most/all of the cores are in a low power state or a deep sleep mode, and the graphics are essentially tuned off, and the fabric is powered down as much as possible. As we move to denser process nodes with bigger transistor budgets, more of those transistors are being used to create individual power and frequency domains in order to manage how a processor deals with sub-dividing its parts for low powered modes.
On top of that, logic needs to be applied to manage all the different domains, and it needs to be designed such that when the parts that are turned off are needed again, they can be powered up with no noticeable delay to the end user.
With every generation of laptop product, both Intel and AMD continually introduce new features and better control over the different compute and interconnect blocks within mobile processors where it matters the most. For Tiger Lake, Intel has an updated its autonomous dynamic voltage/frequency scaling (DVFS) algorithms to take into account bandwidth requirements for a given workload.

This is done on top of other power optimizations at an SoC level, such as even better clock gating for the CPU cores and better voltage regulator efficiency for the integrated regulators. With Tiger Lake, even the PCIe, USB and thermal sensors now occupy their own domains for sleep states. When a component needs to be put in sleep, if it contains important data that often needs to be ‘saved’ somewhere for when it is restored: Intel now has improved hardware-based save and restore logic for this purpose, going beyond Ice Lake’s offerings. Exactly how much change has been made hasn’t been quantified, but the idea is that all these small adjustments will add up over time.
Tiger Lake Performance and Products
For Tiger Lake, Intel has made some substantial changes over its previous Ice Lake design. If you’ve skipped to the end of this article without reading the pages in between, then in my opinion you should know that new 10nm SuperFin is what I would consider one of the big talking points.
SuperFin and Willow Cove Frequencies
Intel has done away with the 10+ and 10++ naming, and 10nm SuperFin (10SF) has replaced 10+.
It is called SuperFin because Intel has refined its next generation transistor fins and the metal stack in its manufacturing in order to enable a wider range of performance and efficiency compared to the base 10nm process. What this means is that Intel claims that at the same power as Ice Lake, Intel shows Tiger Lake as having a +10% frequency uplift, going from 4.0 GHz up to 4.5 GHz. Not only this, but because the new 10SF allows a wider range, when the core is pushed, Tiger Lake should move within a hair of 5.0 GHz.
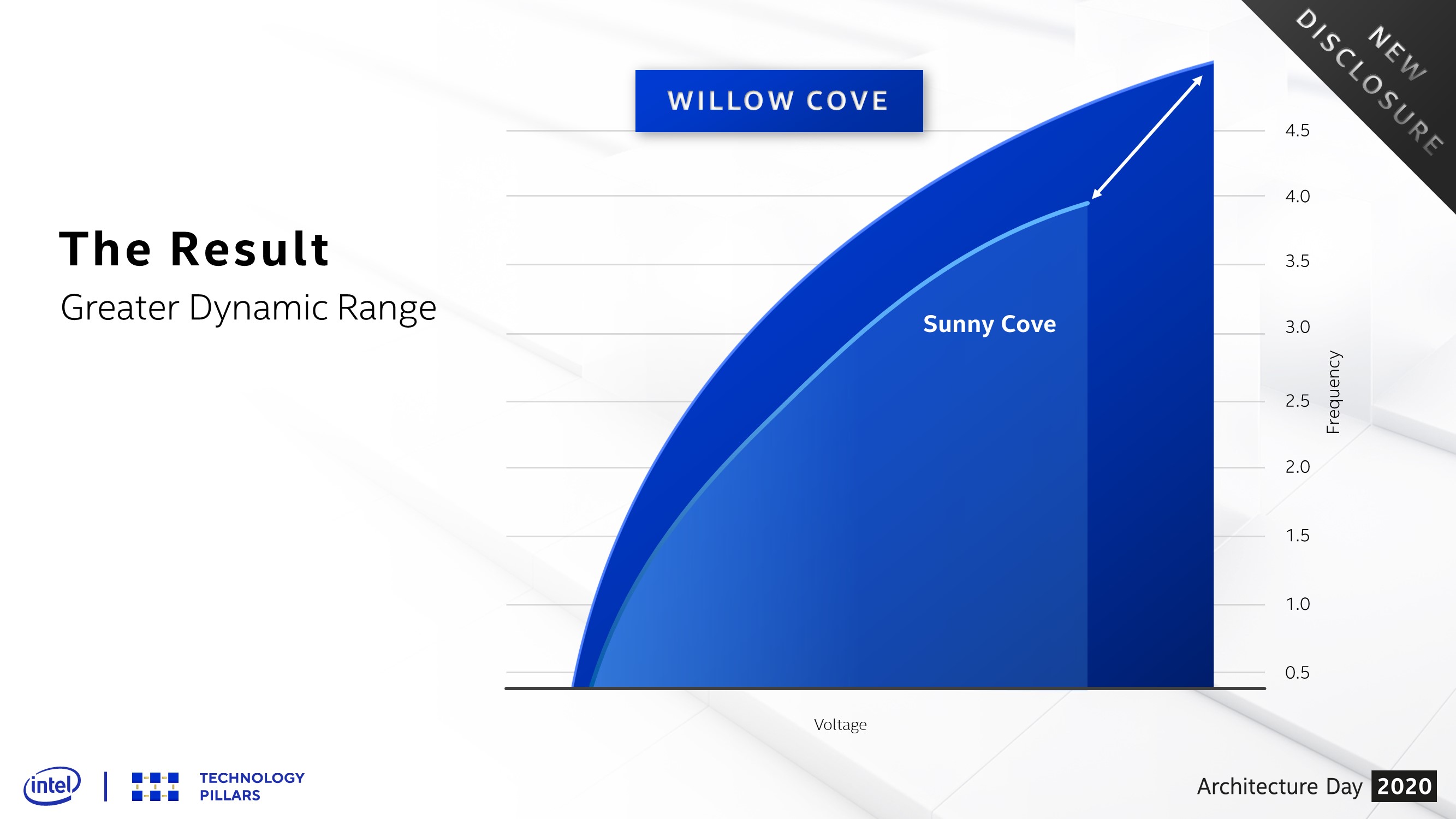
That would be a +20% direct frequency uplift in peak performance, bigger than a traditional intra-node manufacturing update, before we even talk about any microarchitecture improvements.
On the core design front, comparing the new Willow Cove core to the Ice Lake core, we have very few changes. Most of it is identical, except for the L2 cache (+150%, now non-inclusive) and the L3 cache (+50%) getting bigger and new memory security measures being implemented. Intel has quoted that it went after frequency rather than IPC, as +20% frequency is more akin to a node change in performance, whereas chasing IPC in this product would not have produced the same change. As it stands, we predict a small single digit uplift in IPC. We will have to wait until the next generation product to see IPC increase again.
Xe Graphics
Tiger Lake will also be the launch vehicle for Intel’s Xe Graphics strategy. Onboard we get 96 Xe-LP execution units, up 50% from 64, running at a frequency at least 50% higher, at 1600+ MHz.
Intel is advertising the graphics performance increase over Ice Lake of around 2x all-in. Tiger Lake supports not only DDR4-3200 and LPDDR4X-4267, but LPDDR5-5400 as well, which will be good for 86.4 GB/s of bandwidth that would be great for the integrated graphics. Though it should be noted that laptop vendors aren’t jumping on the LPDDR5 bandwagon immediately, as prices are high and volumes are low / going into smartphones. LPDDR5 is going to be more of a mid-cycle update for Tiger Lake.
The Rest
On top of performance, Tiger Lake also expands its IO and Display capabilities, enabling Thunderbolt 4 natively, as well as four 4K displays and support for AV1 decode among other things. Intel states that TGL supports PCIe 4.0, and the amount of lanes will scale with core count (numbers point to an 8-core Tiger Lake in the future). Intel didn’t go into lane counts, but based on a number of pointers on Intel’s slides, we believe the four core version of the chip has a 4.0 x4 link.
The official launch for the Intel’s 11th Gen Core Mobile processors (Tiger Lake) is going to be on September 2nd. At that time we expect to see some of Intel’s OEM partners showcase product designs ahead of Q4 launches in time for the holiday season. There are still a number of questions on the chip, Intel’s ability to manufacture it, how it will compete against AMD, and so forth, which we expect to learn closer to that time.
Tiger Lake on 10 W to 65 W CPUs
As a final thought – one of the first comments made by Intel as part of our briefings was that the Tiger Lake design is going to be scalable, from 10 watts to 65 watts. The current processor we know about today is a four core processor at 15 watts. We’ve already surmised that Intel is preparing an eight core variant, with double the L3 cache, which we suspect to go up to that 65 W mark - however there is a question of where that product would end up. Traditional mobile processors tend to have a ceiling of 45-54 W TDP, and the 65 W space is usually reserved for desktop / socketed processors. Intel previously launched 65 W versions of its Broadwell mobile CPU on the desktop in 2015, and I wonder if we might see something similar here, which would enable Willow Cove, 10SF, and integrated Xe-LP on the desktop.
All of our information today came from Intel’s closed door Architecture Day 2020, held less than 48 hours prior to when this goes public. Aside from my article on Tiger Lake, and Ryan’s article on Intel’s Xe Portfolio, a number of other topics were covered, which we’ll dive into over the next few days.







